Lion Launchpad = Windows 3.1 Program Manager?,
published at 1:07pm on 07/22/11, with 3 Comments
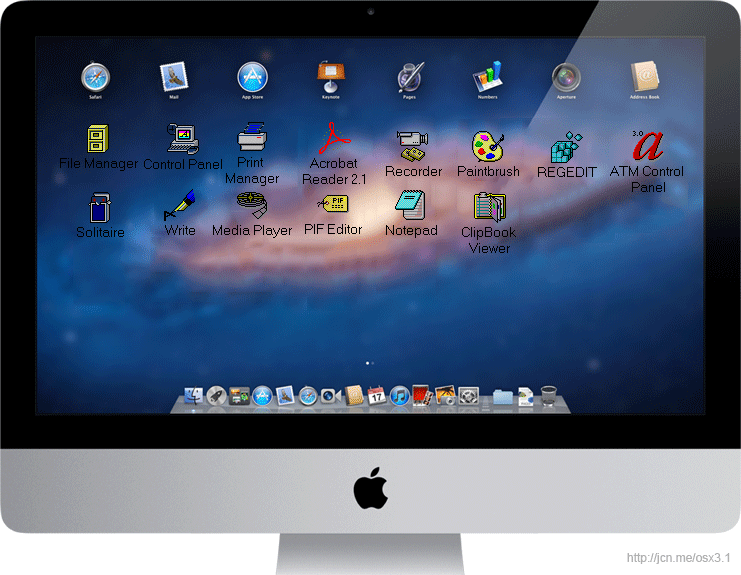
I just saw OS X Lion this morning for the first time, and when I looked at the Launchpad, I couldn’t help but think back to the Program Manager from Windows 3.1.

When I first started using Windows after using my Apple //gs, the first thing I remember was how the Program Manager made absolutely no sense to me. I was used to navigating my directory structure like a tree, collecting like-apps in folders and roughly knowing the layout of my hard drive. The Program Manager threw all of that out and gave me one “launch” window that contained links to all of my programs without any context. I was immediately confused – these weren’t files that were the programs I wanted to run, they were merely pointers to the programs that lived elsewhere on the drive.
Eventually, I got used to this structure and I found myself creating groups for my games, my utilities, my graphics programs. Windows 95 had the same structure, though it was moved from Giant Window to Start Menu. Finally, I got my Titanium Powerbook running OS X and I was back to the Applications folders where I would navigate my computer’s directory structure to find an actual program file to run when I wanted to run a program. Well, except for the Dock.
And now, with Lion, Apple is taking a cue from Microsoft and is decoupling the actual running of programs from the location of the program files themselves. Everything old is new again in computing, eh?
Filed under: Technology, with 3 Comments
On Hiring Exceptional People,
published at 12:07am on 07/09/11, with No Comments
A few weeks ago, I came across an HBR blog post boldly titled “Great People Are Overrated.” There was such a kerfuffle over the first article, that a second one, backing up the first, was subsequently posted. And the main thrust of both articles centered around quotes from the likes of Mark Zuckerberg and Mark Andressen expressing in their entrepreneurial wisdom that to a business, those who are exceptional in their roles are “100 times better” than those who are not (Zuckerberg) and that “five great programmers can completely outperform 1,000 mediocre programmers” (Andreessen). More specifically, in the rush to the top, are companies losing sight of what it means to have a “team” and focusing more on hiring star players who will ultimately burn out?
While I already think that the two approaches are not mutually exclusive, I think that the articles miss two larger points:
First, all teams need leadership
There are actually two things worth mentioning here as they relate to team structure. The first is that any team that wants to grow to any significant size needs to have effective leadership. Not only does there need to be corporate leadership, but in a given team (and from here on out we’ll be talking about engineering teams), once you grow past a handful of developers, there needs to be an individual whose job it is to keep the team motivated, to keep them on schedule, to keep them abreast of the business priorities as they pertain to the product at hand. Namely, the team needs a manager.
The interesting thing that happens when you find exceptional people is that you get to punt on the manager problem. Great engineers will seek to understand the problem space, they will work hard to come up with interesting solutions to the problem that are not only technically correct but also fit within your business model. They will motivate themselves, they will ask hard questions of their leaders, they will build great products and they will improve your business. Your average engineer will not do that. Period.
In addition, having a smaller team of high-quality engineers will keep the organization much flatter, which again lets you defer the problem of managers for a little while. With smaller teams, the managerial indirection to get a concept from a product lead to the developer doing the execution just isn’t needed.
Second, most teams do not need to plan to grow that large
The truth is that you can get a lot done with a small team of very talented individuals. Even Facebook, with its hundreds of engineers operates with very small teams working on each of their individual products. With the trend of companies building single products that do one thing very well, a company’s hiring practices should be focused on hiring the very best people who can build the very best product as fast as they can.
When we made our first hiring push at Indaba Music, I remember having conversations with my partners wondering about the the point at which we were going to have to start hiring engineers simply to fill the seats to get people churning out code. That was four years ago, and while I would love to have a larger team in place than we have now (as it turns out, it’s difficult to hire software developers in New York City right now), we still have not gotten to the point where we’ve needed to hire just to get people in the door.
While it’s tempting to look at a company like IBM that has been around for a hundred years, and to look at the teams that make them tick, it’s also practical to see this as a premature optimization for a business problem that may never actually manifest.
Ultimately, filling your team with star talent is not about celebrating the individual over the collective. Rather, it is about making sure that every single person at your organization is helping to drive your product vision out the door as quickly and as effectively as possible.
Filed under: Observations, Technology, with No Comments
How to Run Tornado in WSGI Mode on DotCloud,
published at 1:06am on 06/13/11, with 3 Comments
Note: Running Tornado on DotCloud requires Tornado 2.0, which includes a bug fix to address an issue where POST requests never return and result in a 504 gateway timeout from DotCloud’s proxy servers.
So, let’s just say that you’re building a new app to deploy to your fancy new dotcloud account, and you’ve decided that, since you know it the best, you are going to build a Tornado app. Well, if you do that, you will quickly learn that this is probably not the best possible choice for you, as Tornado, and all of its async goodness is not going to be available to you yet.
So what to do? Well, let’s say you have your heart set on using Tornado. That’s cool, you’re just going to have to be comfortable running your app as a synchronous WSGI application, and make sure you haven’t used any of those async methods anywhere else in your code. Assuming the best, the first thing is to rename your main app to wsgi.py so dotcloud knows where to find it. Once that’s done, you’re going to want to do is to convert that tornado.web.Application into a tornado.wsgi.WSGIApplication:
application = tornado.web.Application([ (r"/", MainHandler), ])
becomes
import tornado.wsgi import wsgiref.handlers application = tornado.wsgi.WSGIApplication([ (r"/", MainHandler), ])
OK, so that’s cool, and you fire up your application in dotcloud, and you find that you keep getting a 404 thrown back at you from nginx. Well that’s not cool at all, and you start to poke around a bit more, and ultimately, the nice folks at dotcloud tell you that sometimes, WSGI applications just don’t want to know about the SCRIPT_NAME variable in the WSGI params. So let’s go ahead and strip those out.
tornadoapp = tornado.wsgi.WSGIApplication([ (r"/", MainHandler), ]) def application(environ, start_response): if 'SCRIPT_NAME' in environ: del environ['SCRIPT_NAME'] return tornadoapp(environ, start_response)
So what did we do here? Well, the WSGI handler that dotcloud uses (uWSGI) assumes that there is going to be a variable named “application,” so we define our own “application” that strips out the offending SCRIPT_NAME variable from the environment, then calls down the Tornado WSGI interface and returns it.
And really, that’s all you need to do. Now, it may seem silly to do all of this work when something like web2py would do the trick nicely, but I can think of two reasons not to do that:
First, you already know Tornado, and don’t want to learn something new, which is especially important when you’re trying to just get a Minimum Viable Product out the door.
And second, a fully-supported Tornado has to be coming somewhere down the line, and this way, you’ll be (almost) all ready to redeploy your app as an actual non-blocking Tornado app with minimal changes when the time comes.
Filed under: Technology, with 3 Comments
On business cards (or, why I don’t use Hashable),
published at 11:05am on 05/24/11, with 1 Comment

“Well, that was a Hashable fail,” he said, as we sat around the table, exchanging business cards.
This was, ostensibly, a meeting of people from various parts of the New York tech scene, and we were exchanging little piece of paper with our contact information on them. There were smart phones galore on the table next to our lunches, laptops tucked into bags and iPads at the ready. And yet “let me give you my card” was the phrase most heard as people were packing up to leave.
But I have a confession to make: I like business cards.
Really. While I have finally made the transition from paper calendar to one stored in my phone and on the web, I continue to prefer to carry away from meetings actual physical representations of the people that I have just met. For me, the card carries not only a person’s contact info, but it also gives me a little bit of insight into their personality (or the personality of their company), and it serves as a tangible reminder of the actual, physical, meeting. If I look at the card when I first get it into my hands, and then look at the person who gave it to me, I’ll have a much better chance of remembering the circumstances under which I got it in the first place.
So what actually happens after you hand me a business card?
Step 1. Acquire the card. This step is actually more important than you might first imagine. I always look at the card that I’m receiving so I have a sense of it for when I retrieve it later. The whole point of getting the card is so you can follow-up with the person later, so I try to associate the person with the card. I might even take write a note directly on the card immediately (more on that later).
Step 2. Store the card. Put all of the cards you receive at one time in the same place. This could be a slot in your wallet, or your own business card case, or your shirt pocket. The trick is to keep all of the cards from the same event in the same place, so when you retrieve them, you do them all at once. Far too many times I’ve stuck cards in pants pockets and shirt pockets and notebooks, only to forget at what event I actually received that card, or worse yet, who it was actually from and why I should care. If you’re at a conference, your conference badge holder is a nice place to store everything until it’s time to process.
Step 3. Capture the information on the card. If I actually want to correspond with you in the future, the first thing I do is take a pen and write on the back of your card the date that I met you, the circumstances under which we met, and any other information that I might remember. What we were talking about. What I told you I was going to do when I followed up with you. What your next vacation is going to be. Physical characteristics that might be relevant. What I’m doing here is capturing as much as I can, again in a physical way. By writing it on the card itself, I am making a direct connection between the conversation we had and the actual object that you handed me.
Pro tip: if the card you’re writing on is one of those glossy cards that refuses to take ink, just tear off the top layer of the card to reveal actual writable paper below. If it’s one of those plastic business cards, you’re out of luck.
Step 4. Transfer the information from the business card to my address book. Now this step might seem redundant (or more to the point, the previous step might seem redundant), but for me, the act of writing down the details on the card in Step 3 is a physical memory aid, and it’s very quick – just a few notes. Transferring that data to the computer serves to reinforce the things that I just wrote (the act of reading and then typing it into the computer should help me remember things better), it brings the relevant contact information into an easily retrievable spot, and it means that the information I’ve written in Step 3 is now easily searchable. Not everyone makes it into my address book and by making it a 2-step process, I have the data captured on the card itself in case I decided that I need it for future reference while not cluttering up my personal contact list.
Step 5. Store the cards. I do not have step down at all. All of the cards that I collect are in piles around my desk, roughly grouped chronologically, and sometimes tied together with a rubber band. Please, if you have found a good card storage solution, let me know.
And that’s it. At the end of the process I’ve fixed in my mind and my computer our meeting and your details details in a way that I just haven’t found possible in a purely electronic system.
Filed under: Productivity, Technology, with 1 Comment
On converting from single-AZ RDS to multi-AZ RDS,
published at 8:05pm on 05/04/11, with 1 Comment
A couple of weeks ago, we were bitten by the Amazon AWS outage that affected so much of the internet. We were lucky enough that the outage only affected our main RDS database instance, we did not lose any data, we were able to recover from a snapshot, and we managed to get some great press out of the deal. That said, we decided that we wanted a bit more reliability from our hosting infrastructure, and while most of our system was designed to fail gracefully, our database was a single point of failure that, in this case, failed.
So, while it may not have helped us in this particular instance (due to the nature of Amazon’s outage), we decided that we should convert our database instance from a single instance to one that is backed by Amazon’s Mutli-Availability Zone failover mechanism. Even though, according to Amazon’s own post-mortem, their Multi-AZ instances didn’t failover correctly in this particular outage, I trust that they’ve learned from their mistakes and that, in the future, the failover will work properly.
So what does this actually mean? It means that there our Mysql database instance has a hot spare always at the ready in case anything catastrophic happens to our master. In case of any sort of failure to our main database, Amazon should detect this and automatically switch us over to the backup. Then, they will bring up a new backup instance for our newly promoted master and we will be protected again from failure. This should all happen transparently and our site should see minimal interruption in the case of this kind of failure. In addition, backups and upgrades are all done on the backup instance, meaning that we should see even more stability in our day-to-day usage. Sounds like a win all around for us.
We had our main database server up and running for about a year I could not for the life of me find any information about how long this conversion would actually take. We have a 30GB large instance living in the US East Availability Zone.
At 9:55 pm EST on a Sunday night I took our site offline and started the conversion process. This consisted solely of clicking a checkbox in the RDS web interface, making sure that the checkbox to apply the changes immediately was checked, and clicked “save.” The conversion process started almost immediately and at 10 minutes later it was done.
I’m not sure if the database was inaccessible that whole time, but I took the site down anyway, just to be safe. All it all, the upgrade was completely transparent to me and required no other intervention on my part.
We’ve seen no adverse affects to this upgrade (other than to our bill – the multi-AZ instances cost twice as much as a non-AZ instance), but for us, the peace of mind is worth it.

Filed under: Technology, with 1 Comment


